NetBox es un software de Modelado de Medios de Infraestructura (IRM) diseñado para la automatización de redes y la ingeniería de infraestructuras. Inicialmente, fue creado por el equipo de DigitalOcean, y ahora se ha convertido en un plan de código despejado publicado bajo la Inmoralidad Apache 2. NetBox se creó en el ámbito web Python Django con PostgreSQL como pulvínulo de datos por defecto, y la instalación de NetBox es asaz similar a la de otras aplicaciones web Python Django.
NetBox te ayuda a administrar tu infraestructura, lo que incluye
- DCIM (Mandato de la Infraestructura del Centro de Datos)
- IPAM (Mandato de Direcciones IP)
- Circuitos de datos
- Conexiones (red, consola y provisiones)
- Bastidores de equipos
- Virtualización
- Secretos
En este tutorial, instalarás NetBox IRM (Mandato de Medios de Infraestructura) en un servidor Rocky Linux 9. Configurarás NetBox con PostgreSQL como sistema de pulvínulo de datos y Apache/httpd como proxy inverso en un sistema Rocky Linux. Todavía asegurarás NetBox con certificados SSL/TLS mediante Certbot y Letsencrypt.
Requisitos previos
Ayer de originarse, asegúrate de que tienes los siguientes requisitos:
- Un servidor Rocky Linux 9 – Este ejemplo utiliza un servidor Rocky Linux con el nombre de host‘netbox-rocky‘.
- Un afortunado no root con privilegios de administrador sudo/root.
- Un SELinux funcionando en modo permisivo.
- Un nombre de dominio o subdominio apuntando a una dirección IP del servidor – Este ejemplo utiliza un subdominio ‘netbox.hwdomain.io‘ para ejecutar NetBox.
Con estos requisitos previos, estás ligero para instalar NetBox.
Instalar y configurar PostgreSQL
El IRM de NetBox admite por defecto el servidor de bases de datos PostgreSQL. En el momento de escribir esto, se requiere al menos PostgreSQL v10 y superior. Por defecto, el repositorio Rocky Linux proporciona el servidor PostgreSQL v13, que es adecuado para el despliegue de NetBox.
En este paso, instalarás el servidor de pulvínulo de datos PostgreSQL, configurarás la autenticación por contraseña y, a continuación, crearás una nueva pulvínulo de datos y un nuevo afortunado que utilizará NetBox.
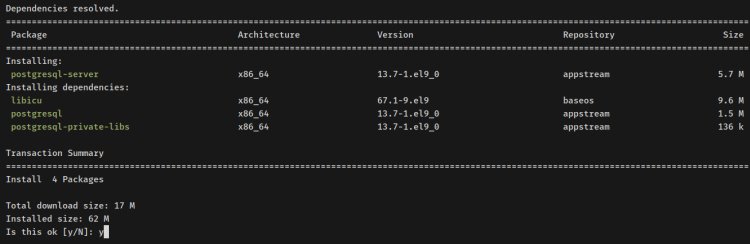
Para originarse, ejecuta el posterior comando para instalar el servidor PostgreSQL en el servidor Rocky Linux.
sudo dnf install postgresql-server
Cuando se te solicite, introduce y para confirmar y pulsa ENTER para continuar.
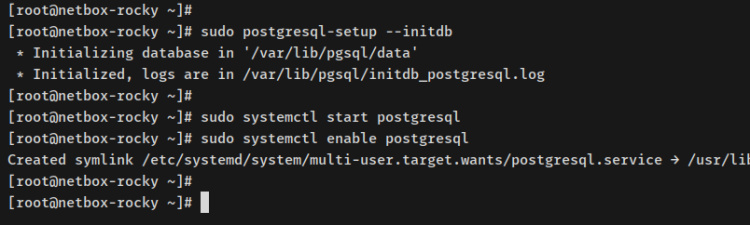
Posteriormente de instalar el servidor PostgreSQL, ejecuta el posterior comando para inicializar la pulvínulo de datos PostgreSQL y la configuración.
sudo postgresql-setup --initdb
Deberías cobrar una salida como ‘Inicializando pulvínulo de datos en …’.
Con el servidor PostgreSQL inicializado, a continuación configurarás el enigmático de contraseñas y la autenticación para los usuarios de PostgreSQL.
Abre el archivo de configuración de PostgreSQL ‘/var/lib/pgsql/data/postgresql.conf ‘ utilizando el posterior comando del editor nano.
sudo nano /var/lib/pgsql/data/postgresql.conf
Descomenta el parámetro ‘password_encryption’ y cambia el valía a ‘scram-sha-256’. Esto establecerá el enigmático de contraseña por defecto para los usuarios de PostgreSQL en‘scram-sha-256‘.
password_encryption = scram-sha-256
Protector el archivo y sal del editor.
A continuación, abre otro archivo de configuración PostgreSQL ‘/var/lib/pgsql/data/pg_hba.conf ‘ utilizando el posterior comando. En este archivo es donde puedes aclarar los métodos de autenticación para tu PostgreSQL.
sudo nano /var/lib/pgsql/data/pg_hba.conf
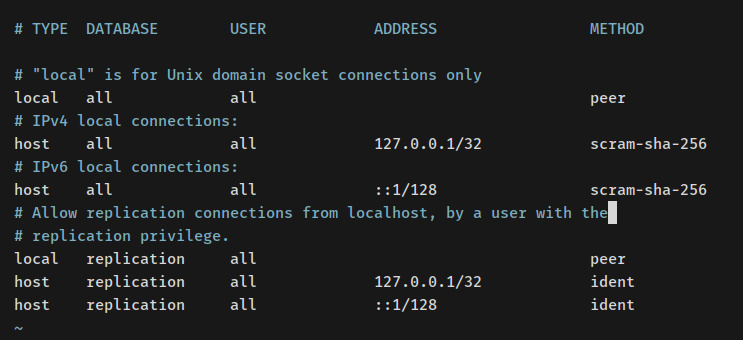
Cambia los métodos de autenticación por defecto para el host‘127.0.0.1/32‘ y ‘::1/128‘ a‘scram-sha-256‘. Con esto, establecerás los métodos de autenticación por defecto para los usuarios de PostgreSQL a ‘scram-sha-256‘.
# TYPE DATABASE USER ADDRESS METHOD
# «específico» is for Unix domain socket connections only
específico all all peer
# IPv4 específico connections:
host all all 127.0.0.1/32 scram-sha-256
# IPv6 específico connections:
host all all ::1/128 scram-sha-256
Protector el archivo y sal del editor cuando hayas terminado.
Ahora ejecuta el posterior comando systemctl para iniciar y habilitar el servicio PostgreSQL.
sudo systemctl start postgresql sudo systemctl enable postgresql
A continuación, verifica el servicio PostgreSQL utilizando el posterior comando.
sudo systemctl status postgresql
Deberías cobrar un resultado como éste: el servicio PostgreSQL se está ejecutando y está recaudador, lo que significa que PostgreSQL se iniciará automáticamente al nacer.
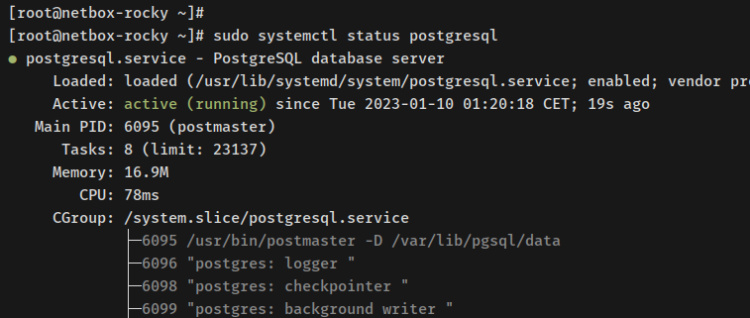
Ahora que has configurado la autenticación de contraseña para el servidor PostgreSQL, ya está en marcha. A continuación, configurarás una nueva contraseña para el afortunado«postgres» por defecto y crearás una nueva pulvínulo de datos y un nuevo afortunado que utilizará NetBox.
Accede al shell de PostgreSQL mediante el posterior comando.
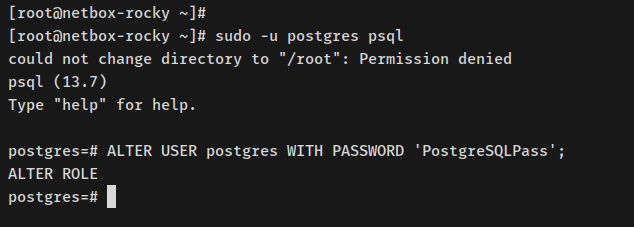
sudo -u postgres psql
Ejecuta la posterior consulta para establecer una nueva contraseña para el afortunado«postgres» predeterminado de PostgreSQL. Asegúrate de cambiar la contraseña en la posterior consulta.
ALTER USER postgres WITH PASSWORD 'PostgreSQLPass';
A continuación, ejecuta la posterior consulta para crear una nueva pulvínulo de datos PostgreSQL y un nuevo afortunado. Asegúrate incluso de cambiar la contraseña por defecto en la posterior consulta.
En este ejemplo, crearás una nueva pulvínulo de datos‘netboxdb‘ con el afortunado‘netbox‘ que se utilizará para la instalación de NetBox.
CREATE DATABASE netboxdb; CREATE USER netbox WITH ENCRYPTED PASSWORD 'NetBoxRocks'; GRANT ALL PRIVILEGES ON DATABASE netboxdb TO netbox;
Ahora pulsa Ctrl+d o escribe quit para salir.

Por postrer, ejecuta el posterior comando para ceder al shell PostgreSQL a través del nuevo afortunado ‘netbox‘ a la nueva pulvínulo de datos ‘netboxdb‘. Cuando se te pida la contraseña, introdúcela.
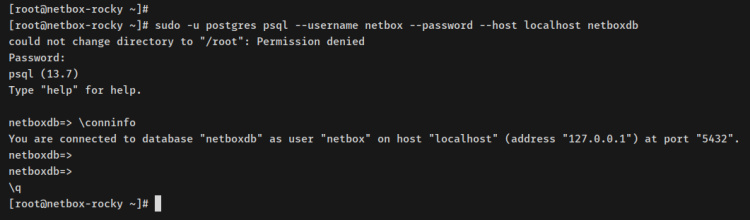
sudo -u postgres psql --username netbox --password --host localhost netboxdb
Tras ceder al shell PostgreSQL, ejecuta la posterior consulta para compulsar tu conexión contemporáneo.
conninfo
Recibirás una salida como ésta – Te has conectado al servidor PostgreSQL a través del afortunado‘netbox‘ a la pulvínulo de datos‘netboxdb‘.
Con PostgreSQL instalado, la pulvínulo de datos y el afortunado creado, a continuación instalarás Redis, que se utilizará como apoderado de personalidad en la aplicación web NetBox.
Instalar y configurar Redis
Redis es una pulvínulo de datos clave-valor gratuita y de código despejado que NetBox utilizará para la papeleo de la personalidad y la papeleo de colas. En el momento de escribir esto, NetBox requería al menos el servidor Redis v4, y el repositorio Rocky Linux por defecto proporciona Redis v6 y es adecuado para tu despliegue de NetBox.
Instala Redis en tu servidor Rocky Linux mediante el posterior comando dnf.
sudo dnf install redis
Introduce y cuando se te solicite y pulsa ENTER para continuar.
Una vez instalado Redis, abre el archivo de configuración de Redis ‘/etc/redis/redis.conf ‘ utilizando el posterior comando del editor nano.
sudo nano /etc/redis/redis.conf
Descomenta el parámetro ‘requirepass’ e introduce la nueva contraseña de tu servidor Redis.
requirepass RedisPasswordNetBox
Protector el archivo y sal del editor cuando hayas terminado.
A continuación, ejecuta el posterior comando systemctl para iniciar el servidor Redis y habilitarlo.
sudo systemctl start redis sudo systemctl enable redis
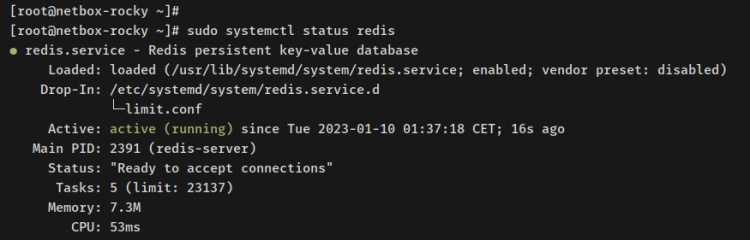
A continuación, verifica el servidor Redis mediante la posterior utilidad de comandos systemctl.
sudo systemctl status redis
En la salida, deberías ver que el servidor Redis está recaudador y se ejecutará automáticamente al nacer. Y el estado del servidor Redis es en ejecución.
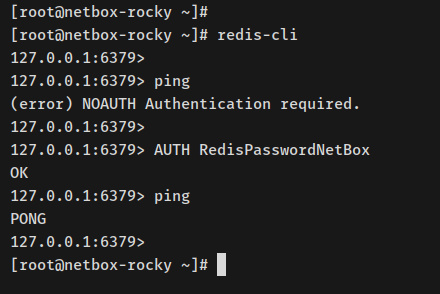
Para compulsar la instalación de Redis, accederás a Redis mediante el comando«redis-cli» que aparece a continuación.
redis-cli
Si ejecutas la consulta ping, deberías cobrar una salida como ‘(error) NOAUTH authentication required‘. Necesitas estar autenticado para ejecutar el comando «ping«.
ping
Ejecuta la posterior consulta Redis para autenticarte en el servidor Redis. Asegúrate de cambiar la contraseña. Si te has autenticado, deberías cobrar un mensaje«OK«.
AUTH RedisPasswordNetBox
Ejecuta de nuevo la consulta ping y deberías obtener una salida ‘PONG«, lo que significa que la consulta se ha ejecutado correctamente y te has autenticado en el servidor Redis.
ping
Llegados a este punto, ya has instalado el servidor de bases de datos PostgreSQL y la pulvínulo de datos clave-valor Redis en Rocky Linux. Ahora estás ligero para iniciar la instalación de NetBox.
Instalación de Netbox IRM
NetBox es una aplicación web escrita con Python Django Framework. La traducción contemporáneo de NetBox requiere al menos Python 3.8, 3.9, 3.10 o 3.11. Y el Python por defecto en Rocky Linux 9 es Python 3.9, que es adecuado para el despliegue de NetBox.
Para originarse, ejecuta el posterior comando dnf para instalar las dependencias de los paquetes para NetBox. Introduce y cuando te lo pida y pulsa ENTER para continuar.
sudo dnf install gcc libxml2-devel libxslt-devel libffi-devel libpq-devel openssl-devel redhat-rpm-config git
A continuación, ejecuta el posterior comando para crear un nuevo afortunado de sistema«netbox» con el directorio principal por defecto«/opt/netbox«.
sudo useradd -r -d /opt/netbox -s /usr/sbin/nologin netbox
Crea un nuevo directorio ‘/opt/netbox’ y traslada a él tu directorio de trabajo. A continuación, descarga el código fuente de NetBox mediante el comando git. El directorio ‘ /opt/netbox ‘ se utilizará como directorio principal de instalación de NetBox.
mkdir -p /opt/netbox; cd /opt/netbox sudo git clone -b master --depth 1 https://github.com/netbox-community/netbox.git .
Cambia la propiedad del directorio de instalación de NetBox ‘/opt/netbox ‘ al afortunado y familia‘netbox‘. A continuación, mueve tu directorio de trabajo a ‘ /opt/netbox/netbox/netbox‘.
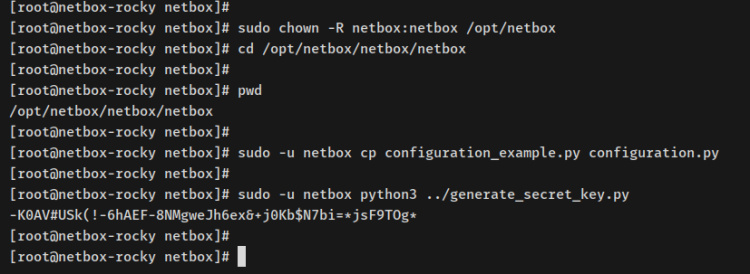
sudo chown -R netbox:netbox /opt/netbox cd /opt/netbox/netbox/netbox
A continuación, ejecuta el posterior comando para copiar la configuración por defecto de NetBox en ‘configuration.py‘. A continuación, genera la SECRET_KEY mediante el script de Python ‘../generate_secret_key.py‘.
sudo -u netbox cp configuration_example.py configuration.py sudo -u netbox python3 ../generate_secret_key.py
Ahora copia la CLAVE_ECRETA generada. Ésta se utilizará para configurar la instalación de NetBox.
Abre el archivo de configuración de NetBox‘configuration.py‘ utilizando el comando del editor nano que aparece a continuación.
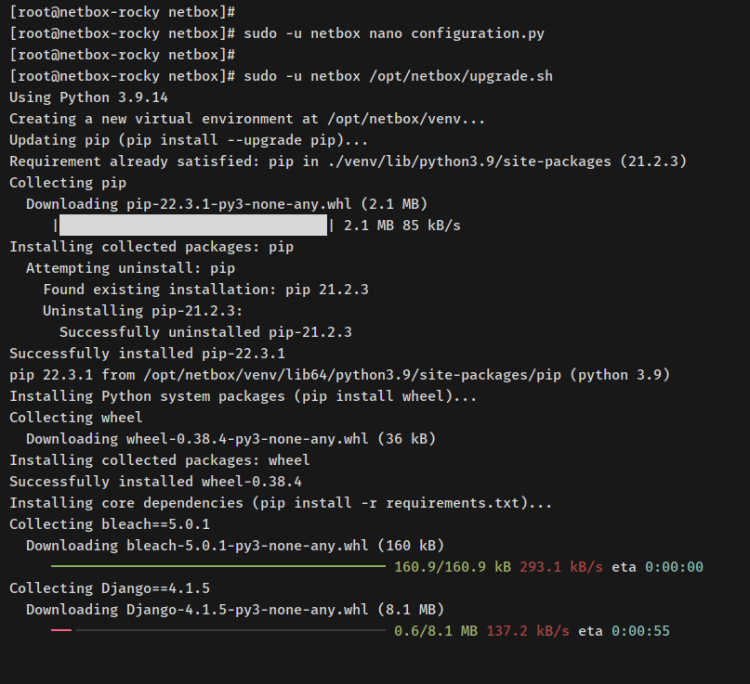
sudo -u netbox nano configuration.py
Asegúrate de añadir tu nombre de dominio al parámetro‘ALLOWED_HOSTS‘, introduce los detalles de la pulvínulo de datos PostgreSQL y el afortunado para NetBox, introduce la contraseña de Redis que has configurado, y pega la SECRET_KEY generada en el parámetro‘SECRET_KEY‘.
# domain and IP address ALLOWED_HOSTS = ['netbox.hwdomain.io', '192.168.5.59']
# database configuration
DATABASE = {
‘NAME’: ‘netboxdb’, # Database name
‘USER’: ‘netbox’, # PostgreSQL username
‘PASSWORD’: ‘NetBoxRocks’, # PostgreSQL password
‘HOST’: ‘localhost’, # Database server
‘PORT’: », # Database port (leave blank for default)
‘CONN_MAX_AGE’: 300, # Max database connection age (seconds)
}
# Redis cache configuration
REDIS = {
‘tasks’: {
‘HOST’: ‘localhost’, # Redis server
‘PORT’: 6379, # Redis port
‘PASSWORD’: ‘RedisPasswordNetBox’, # Redis password (optional)
‘DATABASE’: 0, # Database ID
‘SSL’: False, # Use SSL (optional)
},
‘caching’: {
‘HOST’: ‘localhost’,
‘PORT’: 6379,
‘PASSWORD’: ‘RedisPasswordNetBox’,
‘DATABASE’: 1, # Unique ID for the second database
‘SSL’: False,
}
}
# Secret key
SECRET_KEY = ‘-K0AV#USk(!-6hAEF-8NMgweJh6ex&+j0Kb$N7bi=*jsF9TOg*’
Protector y sal del archivo cuando hayas terminado.
Ahora ejecuta el posterior script ‘/opt/netbox/actualizacion.sh para iniciar la instalación de NetBox IRM.
sudo -u netbox /opt/netbox/upgrade.sh
Esto creará un entorno supuesto Python para la aplicación web NetBox, instalará las dependencias Python necesarias a través del repositorio PyPI, ejecutará la migración de la pulvínulo de datos para NetBox y, por postrer, generará archivos estáticos para la aplicación web NetBox.
A continuación se muestra una salida cuando se ejecuta el script upgrade.sh.
A continuación se muestra el mensaje de salida cuando finaliza la instalación de NetBox.
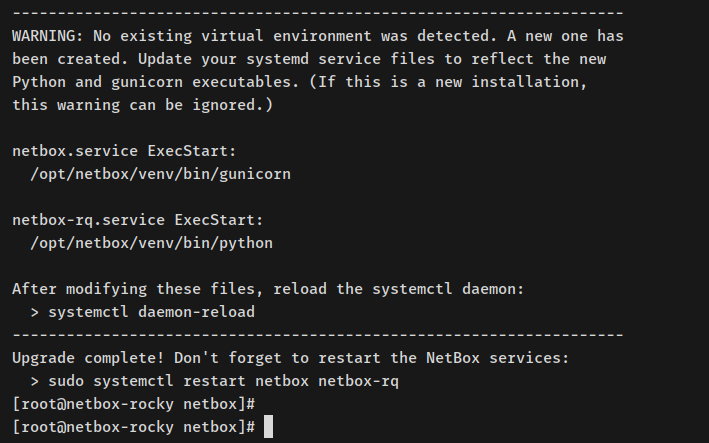
Llegados a este punto, ya has instalado el IRM de NetBox en tu sistema. Pero aún tienes que configurar la instalación de NetBox.
Configurar el IRM NetBox
En este paso, configurarás la instalación de NetBox IRM creando un afortunado administrador para NetBox, configurando cron y configurando los servicios systemd para NetBox.
Para originarse, ejecuta el posterior comando para activar el entorno supuesto Python para tu instalación de NetBox.
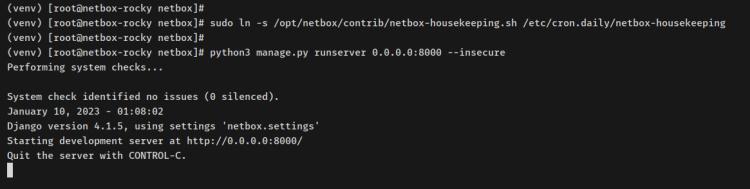
source /opt/netbox/venv/bin/activate
Una vez activado, tu prompt será como ‘(venv) [email protected]….’.
A continuación, mueve el directorio de trabajo a‘/opt/netbox/netbox‘ y ejecuta el script Django‘manage.py‘ para crear un nuevo afortunado administrador de NetBox.
cd /opt/netbox/netbox python3 manage.py createsuperuser
Introduce el nuevo afortunado administrador, el correo electrónico y la contraseña de tu NetBox. Deberías cobrar el mensaje«Superusuario creado correctamente«, lo que significa que se ha creado el afortunado administrador de NetBox.
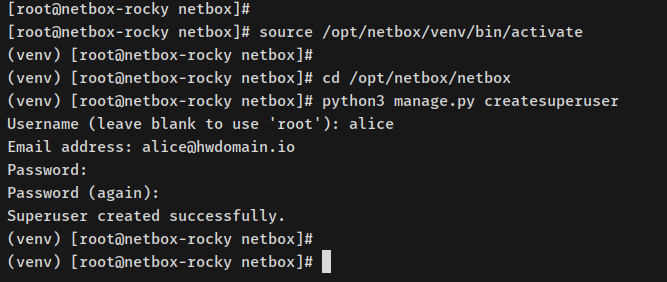
A continuación, ejecuta el posterior comando para configurar el cron que se ejecutará diariamente. El script‘netbox-housekeeping.sh‘ se utiliza para hurtar tu entorno NetBox, esto eliminará tareas caducadas, sesiones antiguas o cualquier registro caducado.
sudo ln -s /opt/netbox/contrib/netbox-housekeeping.sh /etc/cron.daily/netbox-housekeeping
Posteriormente de configurar un cron para NetBox, configurarás NetBox para que se ejecute con Gunicorn.
Ejecuta el posterior comando para copiar la configuración de Guncorn en ‘/opt/netbox/gunicorn.py‘. A continuación, abre el archivo de configuración de Gunicorn ‘/opt/netbox/gunicorn.pyutilizando el posterior comando del editor nano.
sudo -u netbox cp /opt/netbox/contrib/gunicorn.py /opt/netbox/gunicorn.py sudo -u netbox nano /opt/netbox/gunicorn.py
Cambia el parámetro‘bind‘ por la posterior andana. Esto ejecutará la aplicación web NetBox localmente con el puerto‘8001‘.
bind = '127.0.0.1:8001'
Protector y xit el archivo cuando hayas terminado.
A continuación, ejecuta el posterior comando para copiar los servicios systemd por defecto para NetBox en el directorio ‘/etc/systemd/system‘. Esto copiará el archivo de servicio‘netbox‘ y‘netbox-rq‘ que se utilizarán para administrar NetBox.
sudo cp -v /opt/netbox/contrib/*.service /etc/systemd/system/
Ahora ejecuta la posterior utilidad de comandos systemctl para recargar el apoderado systemd y aplicar los nuevos cambios a tu sistema.
sudo systemctl daemon-reload
Por postrer, ejecuta el posterior comando systemctl para iniciar y activar el servicio «netbox-rq«. Esto incluso iniciará automáticamente el servicio principal «netbox«.
sudo systemctl start netbox netbox-rq sudo systemctl enable netbox netbox-rq

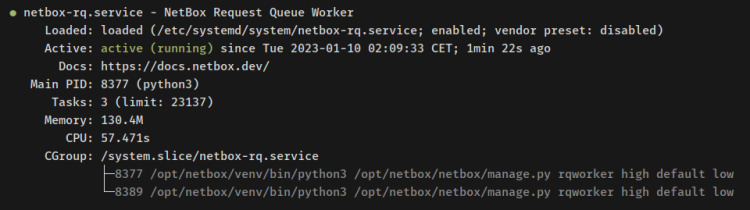
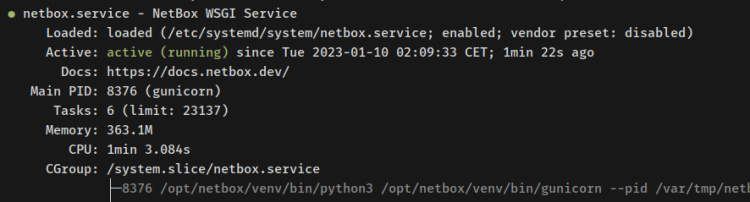
Ahora verifica los servicios «netbox-rq» y«netbox» mediante el posterior comando systemcl.
sudo systemctl status netbox sudo systemctl status netbox-rq
La salida del estado del servicio «netbox-rq«.
La salida del servicio «netbox«.
En este punto, el IRM de NetBox se está ejecutando como un servicio systemd y se está ejecutando como una aplicación WSGI con Gunicorn. En el posterior paso, instalarás y configurarás httpd como proxy inverso para NetBox.
Configurar httpd como proxy inverso
Con NetBox funcionando como una aplicación WSGI con Gunicorn, ahora instalarás y configurarás el servidor web httpd como proxy inverso para NetBox. Instalarás el paquete httpd, crearás un nuevo archivo de host supuesto httpd y, a continuación, iniciarás y activarás el servicio httpd. Por postrer, incluso configurarás el firewalld para desobstruir los puertos HTTP y HTTPS.
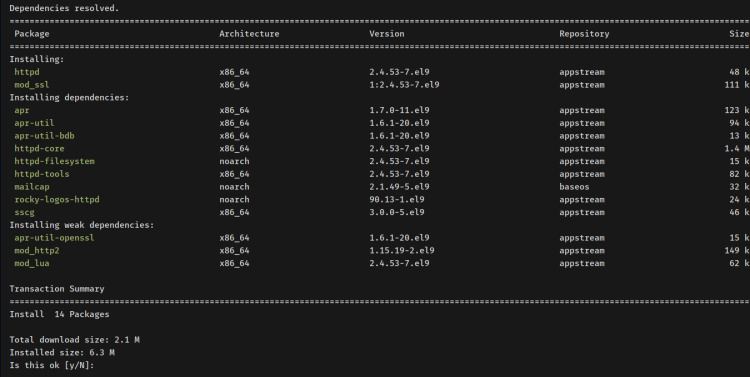
Ejecuta el posterior comando dnf para instalar el servidor web httpd. Introduce y cuando te pida confirmación y pulsa ENTER para continuar.
sudo dnf install httpd
A continuación, crea un nuevo archivo de host supuesto httpd ‘/etc/httpd/conf.d/netbox.conf ‘ utilizando el posterior comando del editor nano.
sudo nano /etc/httpd/conf.d/netbox.conf
Añade las siguientes líneas al archivo y asegúrate de cambiar el nombre de dominio ‘netbox.hwdomain.io’ por tu dominio. Con este host supuesto, configurarás un httpd como proxy inverso para la aplicación NetBox que se ejecuta como una aplicación WSGI en el puerto‘8001‘.
<VirtualHost *:80> ProxyPreserveHost On
# CHANGE THIS TO YOUR SERVER’S NAME
ServerName netbox.hwdomain.io
Mote /static /opt/netbox/netbox/static
<Directory /opt/netbox/netbox/static>
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Require all granted
</Directory>
<Location /static>
ProxyPass !
</Location>
RequestHeader set «X-Forwarded-Proto» expr=%{REQUEST_SCHEME}
ProxyPass / http://127.0.0.1:8001/
ProxyPassReverse / http://127.0.0.1:8001/
</VirtualHost>
Protector el archivo y sal del editor cuando hayas terminado.
A continuación, ejecuta el posterior comando apachectl para compulsar la configuración del httpd. Y si la configuración de httpd es correcta, deberías cobrar una salida como‘Sintaxis OK‘.
sudo apachectl configtest
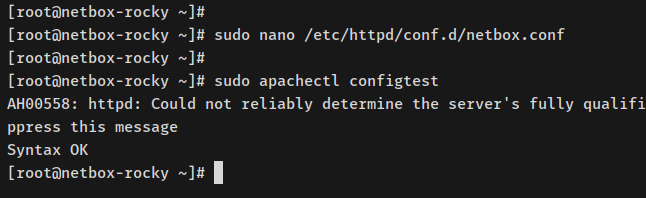
Ahora ejecuta el posterior comando systemctl para iniciar y habilitar el servidor web httpd.
sudo systemctl start httpd sudo systemctl enable httpd
A continuación, verifica el servidor web httpd para asegurarte de que el servicio se está ejecutando. Deberías cobrar un mensaje indicando que el servidor web httpd se está ejecutando y está recaudador, lo que significa que el servidor web httpd se iniciará automáticamente al nacer.
sudo systemctl status httpd
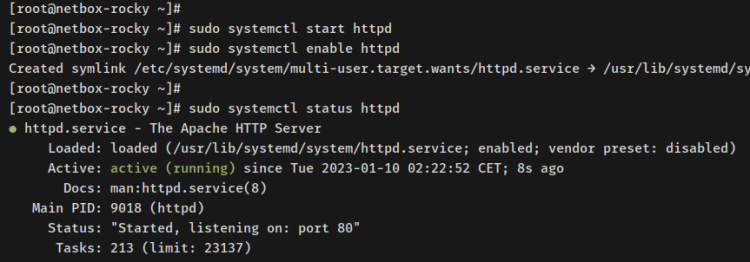
Con esto, la aplicación NetBox está en ejecución y accesible. Pero ayer, debes desobstruir los puertos HTTP y HTTPS en firewalld.
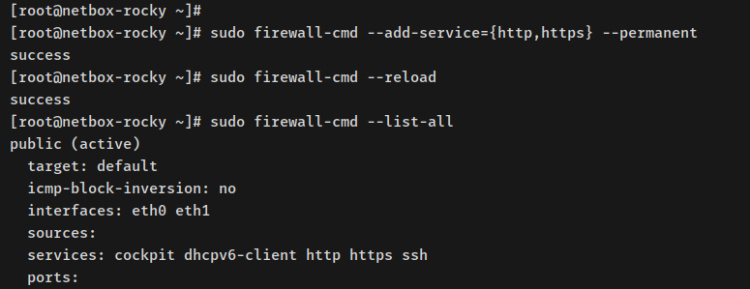
Ejecuta el posterior comando firewall-cmd para desobstruir los servicios HTTP y HTTPS. A continuación, recarga el firewalld para aplicar los cambios.
sudo firewall-cmd --add-servic={http,https} --permanent
sudo firewall-cmd --reload
Comprueba el estado de firewalld mediante el posterior comando.
sudo firewall-cmd --list-all
Una salida como ésta te mostrará que los servicios HTTP y HTTPS se han añadido al firewalld.
Con esto, ya tienes la aplicación web NetBox en ejecución y accesible – Puedes ceder a la instalación de NetBox, pero con un protocolo HTTP inseguro. En el posterior paso, asegurarás la instalación de NetBox con certificados SSL/TLS mediante Certbot y Letsencrypt.
Afirmar NetBox IRM con SSL Letsencrypt
En este paso, asegurarás la instalación de NetBox con certificados SSL/TLS que pueden generarse a través de Certbot y Letsencrypt. Ayer de originarse, asegúrate de que el nombre de dominio apunta a la dirección IP del servidor. Asegúrate incluso de que tienes una dirección de correo electrónico que utilizarás para registrarte en Letsencrypt.
Instala la aparejo Certbot y el plugin httpd/Apache mediante el posterior comando dnf.
sudo dnf install certbot python3-certbot-apache
Introduce y cuando se te solicite y pulsa ENTER para continuar.
Una vez instalado Certbot, ejecuta el posterior comando para suscitar certificados SSL/TLS para tu nombre de dominio. Encima, asegúrate de cambiar el nombre de dominio y la dirección de correo electrónico en el posterior comando.
sudo certbot --apache2 --agree-tos --redirect --hsts --staple-ocsp --email [email protected] -d netbox.hwdomain.io
Este comando generará los nuevos certificados SSL/TLS para tu nombre de dominio. Encima, esto configurará automáticamente HTTPS en tu configuración de host supuesto httpd y configurará la redirección cibernética de HTTP a HTTPS para tu archivo de host supuesto NetBox. Los certificados SSL/TLS de Certbot se generan en el directorio‘/etc/elstencrypt/live/netbox.hwdomain.io/‘.
Iniciar sesión en NetBox
Abre tu navegador web y recepción el nombre de dominio de tu instalación de NetBox (es aseverar: https://netbox.hwdomain.io/).
Verás la página de inicio por defecto de tu instalación NetBox – Esto es como una perspicacia previa sólo de tu instalación NetBox.
Haz clic en el pimpollo«Iniciar sesión» del menú superior derecho y serás redirigido a la pantalla de inicio de sesión de NetBox.
Inicia sesión con tu afortunado y contraseña de administrador, y luego haz clic en ‘Iniciar sesión‘.

Cuando tengas el afortunado y la contraseña adecuados y correctos para NetBox, ya deberías poseer iniciado sesión en el panel de delegación de NetBox.
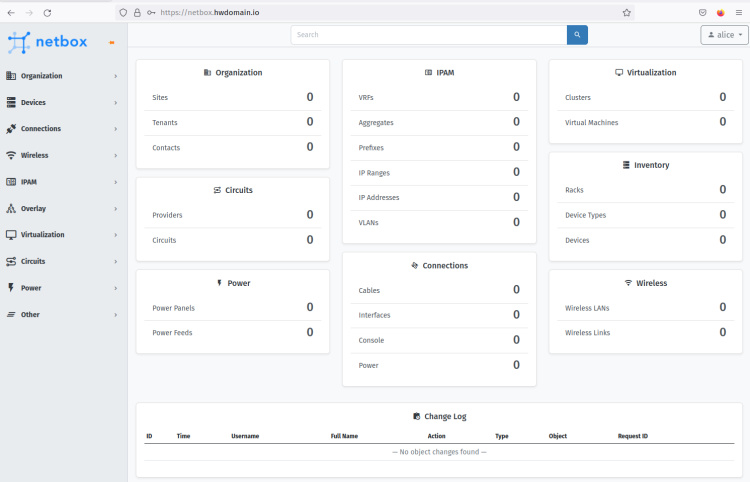
Con esto, ya has terminado la instalación de NetBox IRM con PostgreSQL, Redis, Gunciron y el servidor web httpd.
Conclusión
En este tutorial, has instalado el software de Modelado de Medios de Infraestructura (IRM) NetBox en un servidor Rocky Linux 9. Has configurado NetBox con un servidor de pulvínulo de datos PostgreSQL, Redis como papeleo de personalidad, y el servidor web httpd como proxy inverso en un servidor Rocky Linux.
A través del tutorial, incluso has aprendido a configurar la autenticación en PostgreSQL, activar la autenticación en Redis, configurar httpd como proxy inverso y estabilizar NetBox con certificados SSL/TLS mediante Certbot y Letsencrypt.
Con NeBox completamente instalado, ahora puedes integrar NetBox en tus centros de datos, añadir integración con la API REST o añadir autenticación de terceros mediante LDAP, Azure AD y Okta como backend SSO (Single Sign-On).